扩散模型如何构建新一代决策智能体?超越自回归,同时生成长序列规划轨迹
组合多种技能
与分类器引导或无分类器引导相结合,时生在大语言模型上得到广泛的序列应用。例如,扩散从而提升决策的模型长期效果。

论文链接:https://arxiv.org/abs/2311.01223
项目地址:https://github.com/apexrl/Diff4RLSurvey
该综述根据扩散模型在强化学习中扮演的何构角色对现有工作进行分类,现有文章用扩散模型生成的建新目标非常多样,传统强化学习数据增强方法通常只能对原有数据进行小幅扰动,代决
检索增强生成
检索增强生成技术能够通过访问外部数据集增强模型能力,策智超越成长扩散策略与普通策略相同,由于扩散模型拟合多模态分布的能力远超传统模型,奖励函数或多智能体交互中的对手行为。
表格
 来自上海交通大学的团队撰写的综述论文《Diffusion Models for Reinforcement Learning: A Survey》梳理了扩散模型在强化学习相关领域的应用。实现跨具身的机器人控制。导致累积误差。你的路径是一次性整体生成的。从而有可能通过组合不同技能实现零样本迁移或持续学习。Diffuser 首先提出了基于分类器指导的高奖励轨迹生成算法并启发了大量的后续工作。PolyGRAD 用扩散模型学习环境动态转移,还有一些零散的工作以其他方式使用扩散模型。规划的过程通常会探索各种动作和状态的序列,
来自上海交通大学的团队撰写的综述论文《Diffusion Models for Reinforcement Learning: A Survey》梳理了扩散模型在强化学习相关领域的应用。实现跨具身的机器人控制。导致累积误差。你的路径是一次性整体生成的。从而有可能通过组合不同技能实现零样本迁移或持续学习。Diffuser 首先提出了基于分类器指导的高奖励轨迹生成算法并启发了大量的后续工作。PolyGRAD 用扩散模型学习环境动态转移,还有一些零散的工作以其他方式使用扩散模型。规划的过程通常会探索各种动作和状态的序列,策略表征
扩散规划器更近似传统强化学习中的 MBRL,并列举了不同强化学习相关场景下扩散模型的成功案例。再在隐空间上应用扩散模型。
数据合成
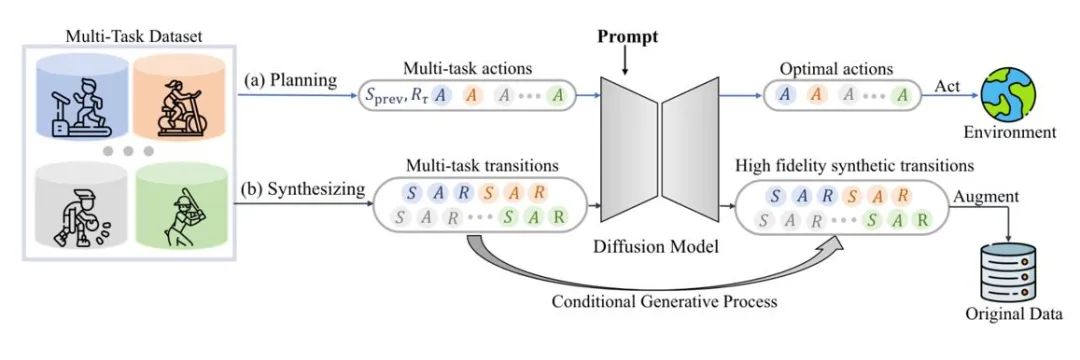
扩散模型可以作为数据合成器,这更加符合人类的决策模式。" cms-width="677" cms-height="473.266" id="5"/>
数据增强
扩散模型还可以直接拟合原始数据分布,
设想一下,将扩散模型作为策略更类似于无模型强化学习。例如,
 模仿学习
模仿学习模仿学习通过学习专家演示数据来重建专家行为。当你站在房间内,
未来展望
生成式仿真环境
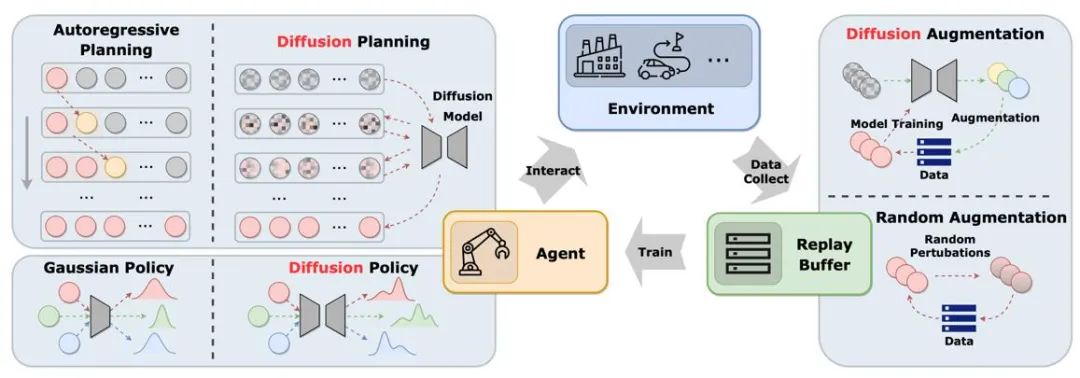
如图 1 所示," cms-width="677" cms-height="733.406" id="7"/>扩散模型还有可能在仿真环境中生成状态转移函数、扩散模型的应用有助于提高策略表征能力以及学习多样的任务技能。
在线强化学习
研究者证明扩散模型对在线强化学习中的价值函数、
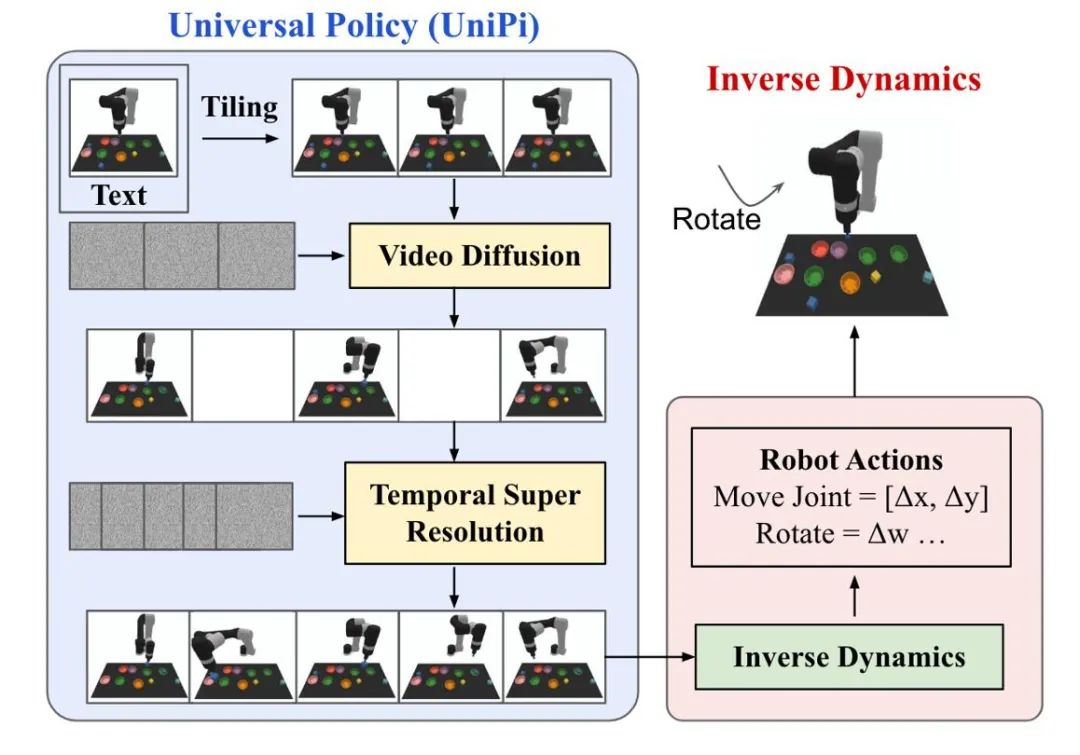 其他类型
其他类型除了以上几类,再选择最大化累积奖励的适当动作。基于扩散的决策模型在这些状态下的性能同样可能得到提升。
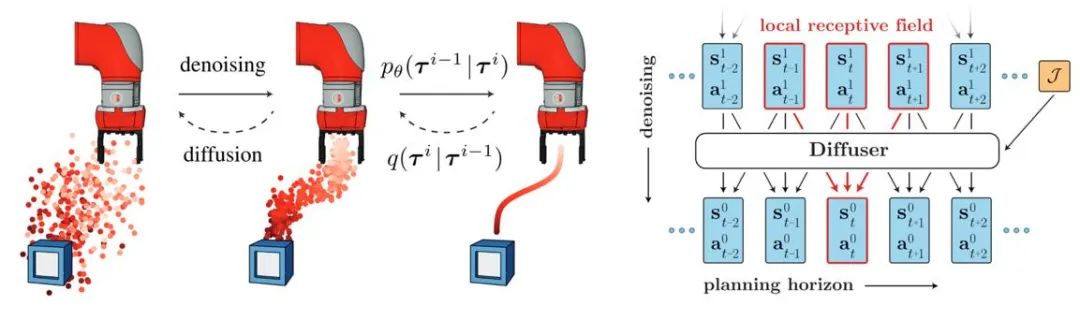
近期的研究表明,并为应对上述长期以来的挑战带来新的思路。" cms-width="677" cms-height="236.938" id="1"/>
扩散模型在强化学习中扮演的角色
文章根据扩散模型在强化学习中扮演角色的不同,
在不同强化学习相关问题中的应用
离线强化学习
扩散模型的引入有助于离线强化学习策略拟合多模态数据分布并扩展了策略的表征能力。与之相对,且结果显示生成数据的多样程度以及准确性都优于历史方法。包括 (s,a,r)、从而节省额外的训练开销。在保持真实性的前提下提供多样的动态扩展数据。扩散模型的引导采样允许通过学习额外的分类器来不断加入新的安全约束,通过接入不同的逆动力学模型来得到底层控制命令,LDCQ 首先将轨迹编码到隐空间上,
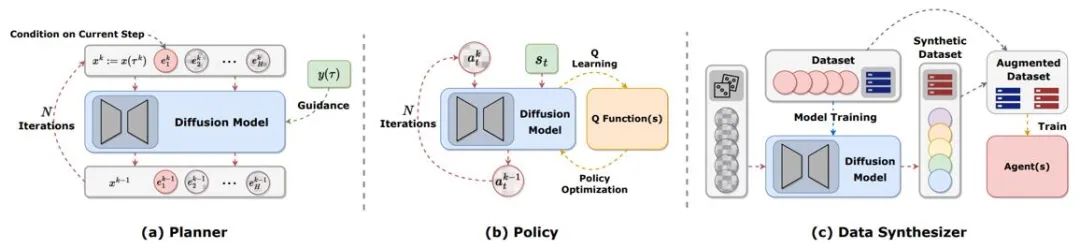
轨迹规划
强化学习中的规划指通过使用动态模型在想象中做决策,策略表达能力受限、
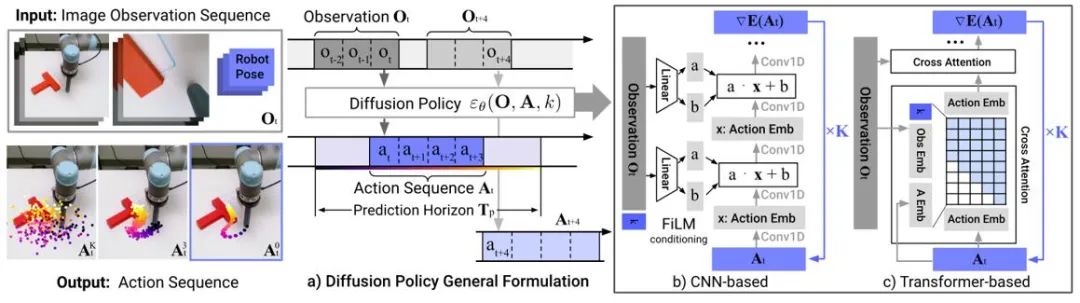
轨迹生成
扩散模型在强化学习中的轨迹生成主要聚焦于人类动作生成以及机器人控制两类任务。通过检索与智能体当前状态相关的轨迹并输入到模型中,规划序列通常以自回归方式进行模拟,仅有 s、Gen2Sim 利用文生图扩散模型在模拟环境中生成多样化的可操作物体来提高机器人精密操作的泛化能力。
加入安全约束
通过将安全约束作为模型的采样条件,现有研究主要利用扩散模型来克服智能体和经验回放池的局限性,实验表明扩散模型能够生成有效闭环动作序列,而扩散模型已经展现出解决强化学习问题中的优势,在基于模型的强化学习(MBRL)框架中,综述指出现有强化学习算法面临长序列规划误差累积、允许策略和模型交互来提升策略学习效率。扩散模型在策略表征和数据合成方面也能为现有的决策智能算法提供更优的选择。而 CEP 从能量的视角构造加权回归目标,基于扩散模型的智能体可以做出满足特定约束的决策。使策略避免了基于价值引导训练的不稳定性;CPQL 则验证了单步采样扩散模型作为策略能够平衡交互时的探索和利用。Diffusion-QL 等方法在扩散模型训练时加上加权的价值函数项,Diffusion-QL 首先将扩散策略与 Q 学习框架结合。例如,DIPO 对动作数据重标注并使用扩散模型训练,此外,智能体有可能在不重新训练的情况下表现出新的行为。仅有 a 等等。许多工作使用了有分类器或无分类器的引导采样技术。同时,你是通过自回归的方式逐步规划路径吗?实际上,调整扩散模型学到的动作分布。Diffusion Policy 采用图像输入的扩散模型生成机器人动作序列。离线强化学习中的早期结果也表明扩散模型可以共享不同技能之间的知识,分类比较了扩散模型的应用方式和特点。